Using Blueprint Validation and Confluence Fields Together
Confluence Fields plugin for Atlassian JIRA provides reporting via builtin Mondrian server. All Confluence custom fields you define are reported in MS Excel pivot using XMLA datasource plugin as described in Using Mondrian with Confluence Fields.
However default XMLA schema is very basic: Confluence field-derived OLAP dimensions are flat, no hierarchies are defined. That makes sense as Confluence fields only keep Confluence page's id and title, no other information from Confluence is stored. But what if you need a more complex reporting? Suppose that you have a 'Clients' custom field that sources its values from a Client blueprint in your Confluence server. The blueprint has a field named 'Country' that you want to use to group your customers for JIRA reporting. Let's keep the blueprint very simple:
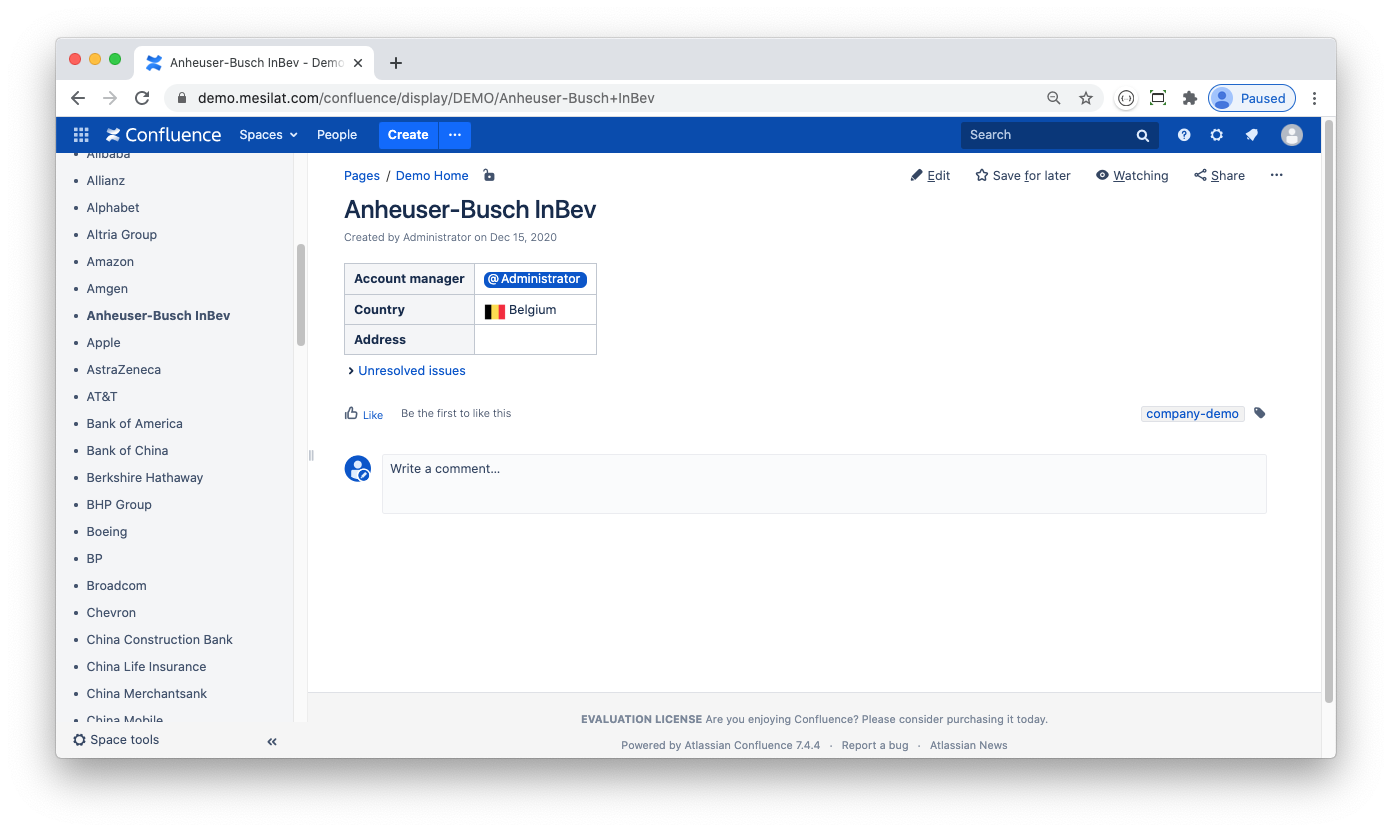
To get the Country information in MS Excel pivot I do the following:
Install the Blueprint Validation plugin for Confluence. The plugin is used to parse my Confluence pages to JSON and to check them against JSON schema to make sure that the data entered is valid
Develop and deploy a custom Confluence server plugin that publishes JSON data to a JIRA server
Develop and deploy a custom JIRA server plugin that consumes the JSON data and saves it to the JIRA database
Develop a Mondrian schema that defines OLAP dimensions with hierarchies that use the data saved
As a result I get an Excel pivot that features the required data grouping:
Confluence Part
In order to have my Confluence blueprint parsed and validated I have to follow some formatting rules as described in Blueprint Validation Markup. Take a look at an example:
<ac:layout><ac:layout-section ac:type="single"><ac:layout-cell><table class="wrapped"><colgroup> <col/> <col/> </colgroup><tbody><tr><th>Account manager</th><td class="dsattr-manager dsvalidate-manager"></td></tr><tr><th>Country</th><td class="dsattr-country dsvalidate-country"></td></tr><tr><th>Address</th><td class="dsattr-address"><ac:placeholder>Mailing address</ac:placeholder></td></tr></tbody></table>...</ac:layout-section></ac:layout>This is a standard Confluence blueprint markup with some notable modifications, namely <TD>-tag class attributes: dsattr-manager, dsattr-country, etc. These define JSON attributes (note the data object in the screenshot below):
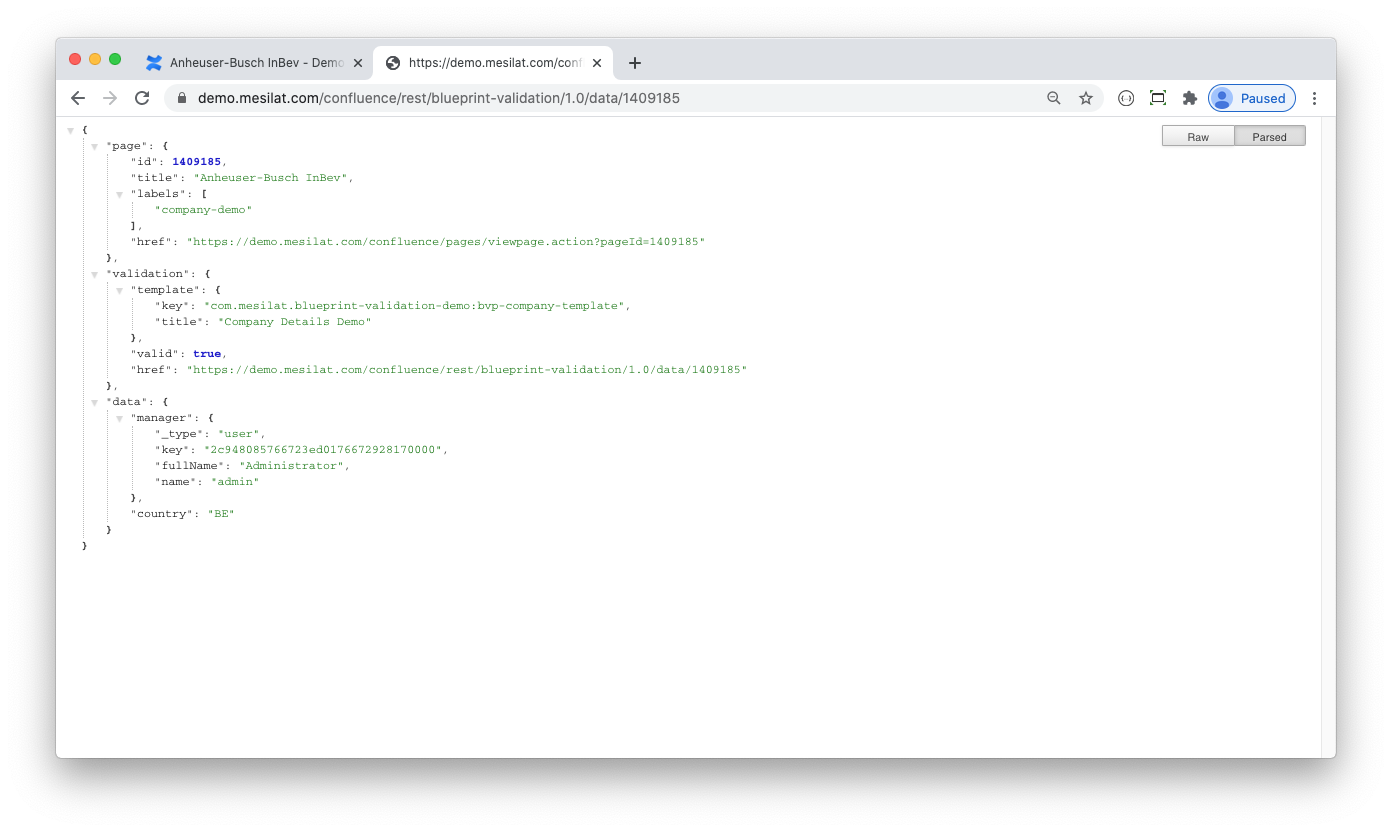 To get the data published to my JIRA server I created a custom Confluence plugin that handles
DataValidateEvent. Let's take a closer look at the plugin's dataObjectValidateEvent method:
To get the data published to my JIRA server I created a custom Confluence plugin that handles
DataValidateEvent. Let's take a closer look at the plugin's dataObjectValidateEvent method:
@EventListenerpublic void dataObjectValidateEvent(DataValidateEvent event) { if (!templateKey.equals(event.getTemplateKey())) { LOGGER.debug(String.format("DataValidateEvent for template=%s; handler is %s, aborting", event.getTemplateKey(), templateKey)); return; } else { LOGGER.debug(String.format("DataValidateEvent for template=%s; processing...", event.getTemplateKey())); }First I need to make sure that Confluence page matches my blueprint. Blueprint Validation plugin publishes DataValidateEvent to all consumers without any filtering, so I implement this filtering myself.
The event object contains JSON data serialised to string, so I parse it and add some extra data for JIRA server:
JsonNode node = mapper.readTree(event.getData());if (!node.isObject()) { throw new RuntimeException("Unexpected data object");}ObjectNode obj = (ObjectNode)node;obj.put("id", page.getId());obj.put("title", page.getTitle());I use Atlassian ApplicationLink interface to communicate to JIRA:
ApplicationLink jira = appLinkService.getPrimaryApplicationLink(JiraApplicationType.class);if (jira == null) { LOGGER.warn("No JIRA application link configured"); event.setValid(false); event.addMessage("No JIRA application link configured"); return;}...ApplicationLinkRequestFactory reqFactory = jira.createAuthenticatedRequestFactory();reqFactory .createRequest(Request.MethodType.POST, endpoint) .addHeader("content-type", "application/json; charset=UTF-8") .setRequestBody(mapper.writerWithDefaultPrettyPrinter().writeValueAsString(obj)) .executeAndReturn((com.atlassian.sal.api.net.Response response) -> ...Finally, I need to guarantee that the data is actually received by JIRA. If any error happens the plugin must inform a user, so I wrap my code in try-catch...
try { ...} catch (Throwable ex) { event.setValid(false); event.addMessage("Failed to push changes to JIRA server: " + ex.getMessage()); LOGGER.warn("Failed to push changes to JIRA server", ex);}...and deny page save if it cannot be published to JIRA:
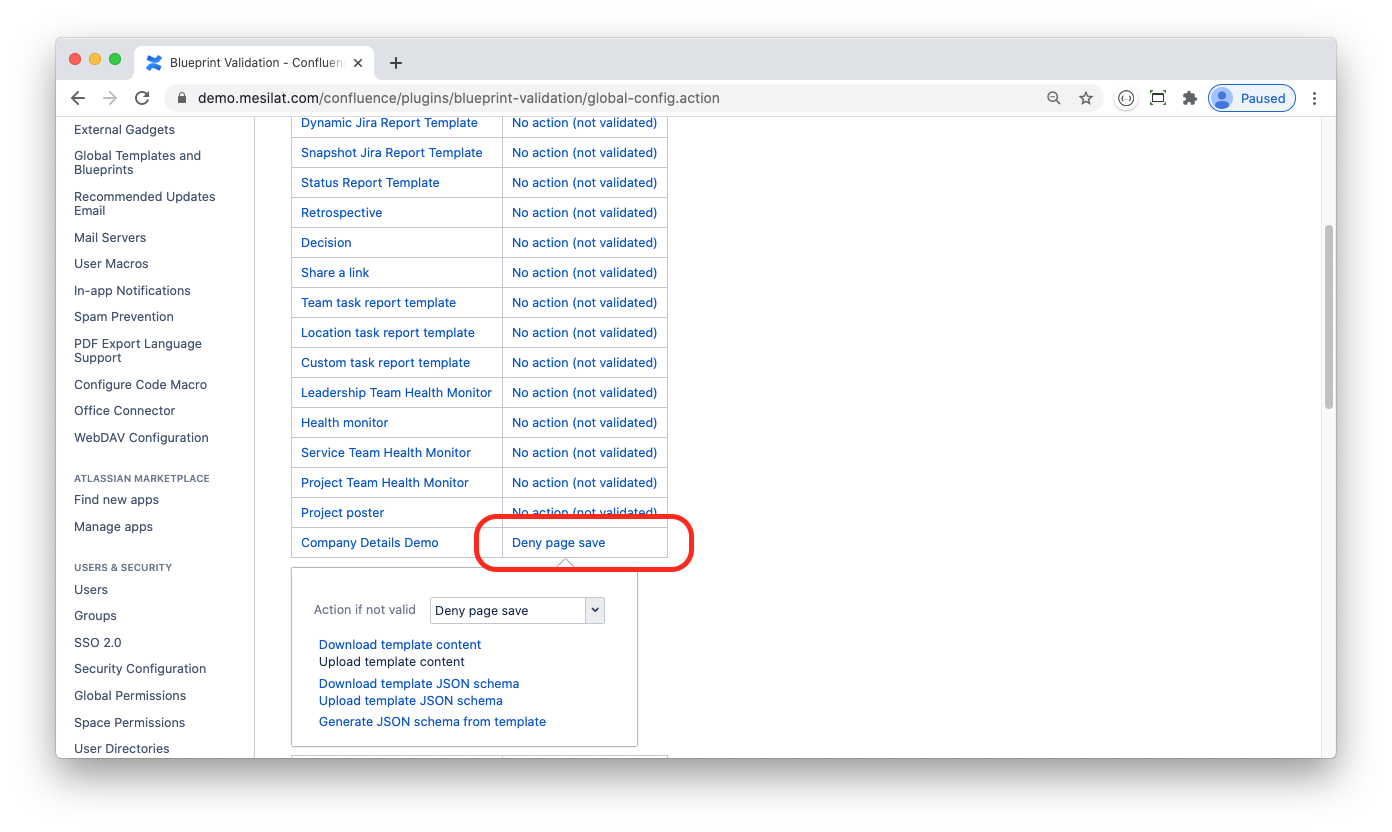
JIRA Part
On the JIRA server side I need to develop an endpoint that consumes the client data and stores it to a database table. I define the table using Atlassian AO:
@Preloadpublic interface Company extends RawEntity<Long> { public static String TABLE = "AO_2CAE32_COMPANY"; @NotNull @PrimaryKey(value = "ID") Long getID(); @StringLength(255) String getTitle(); void setTitle(String title); @Indexed @StringLength(255) String getManager(); void setManager(String category); @Indexed @StringLength(2) String getCountry(); void setCountry(String country);}The save method is very simple:
@Overridepublic void save(ObjectNode company) { ao.executeInTransaction(() -> { Long id = Util.getLong(company, "id"); Company c = ao.get(Company.class, id); if (c == null) { c = ao.create(Company.class, new DBParam("ID", id)); } c.setTitle(Util.getText(company, "title")); c.setCountry(Util.getText(company, "country")); c.setManager(Util.getText(company, "manager", "fullName")); c.save(); return null; });}I built and deployed the plugin to my JIRA server then tested to make sure that the Company table is actually populated. As Atlassian AO adds some prefixes to custom tables, take a note of the actual name of the Company table – in case of blueprint-validation-demo-companion plugin it is called AO_2CAE32_COMPANY.
Now that data is piped from Confluence to JIRA let's get to Mondrian schema.
Mondrian Part
Confluence Fields plugin uses Mondrian v4 schema format. You can download the default schema file as described in the documentation and use it as a sample.
Make sure that WORKLOG query contains required Confluence custom fields. My JIRA's Clients custom field is cf_11100 so the query definition looks as follows:
<Query alias="WORKLOG"><ExpressionView><SQL dialect="postgresql"><![CDATA[SELECTjiraissue.ID,concat(project.pkey, '-', jiraissue.issuenum) as ISSUEKEY,jiraissue.PROJECT as PROJECTID,COALESCE(jiraissue.issuetype, '-1') as TYPEID,app_user.lower_user_name as AUTHOR,DATE(worklog.CREATED) as CREATED,DATE(worklog.STARTDATE) as STARTED,cube."TIME_WORKED" / 3600 as TIMEWORKED,cube.cf_11100_idFROMjiraissueINNER JOIN project ON jiraissue.PROJECT = project.IDINNER JOIN worklog ON jiraissue.ID = worklog.issueidINNER JOIN "AO_9417FD_WORKLOG_CUBE" cube ON jiraissue.ID = cube."ISSUE_ID" and worklog.id = cube."LOG_ID"INNER JOIN app_user ON app_user.user_key = worklog.author]]></SQL></ExpressionView></Query>I defined CLIENTS query and made sure it contains all data needed (including the Country column):
<Query alias="CLIENTS" keyColumn="id"><ExpressionView><SQL dialect="postgresql"><![CDATA[SELECT "ID" as id, "TITLE" as title, "COUNTRY" as country FROM "AO_2CAE32_COMPANY"]]></SQL></ExpressionView></Query>The matching dimension has the Country column in a hierarchy:
<Dimension name="Clients" table="CLIENTS" key="Client"><Attributes> <Attribute name="Client" keyColumn="id" nameColumn="title" hasHierarchy="false" /> <Attribute name="Country" keyColumn="country" hasHierarchy="false" /></Attributes><Hierarchies> <Hierarchy name="Client" allMemberName="All Clients"> <Level attribute="Client" /> </Hierarchy> <Hierarchy name="Country > Client" allMemberName="All Clients"> <Level attribute="Country" /> <Level attribute="Client" /> </Hierarchy></Hierarchies></Dimension>Finally I reference Clients dimension in a Worklog cube:
<Cube name="Worklog"><Dimensions><Dimension source="Issue" /><Dimension source="Project" /><Dimension source="Type" /><Dimension source="User" name="Worker" /><Dimension source="LogDate" name="Created" /><Dimension source="LogDate" name="Start" /><Dimension source="Clients" /><Dimension source="Contracts" /><Dimension source="Products" /></Dimensions><MeasureGroups><MeasureGroup table="WORKLOG"><Measures><Measure aggregator="count" column="id" name="Worklogs count" /><Measure aggregator="sum" column="timeworked" name="Time Spent" /></Measures><DimensionLinks><ForeignKeyLink dimension="Issue" foreignKeyColumn="id" /><ForeignKeyLink dimension="Project" foreignKeyColumn="projectid" /><ForeignKeyLink dimension="Type" foreignKeyColumn="typeid" /><ForeignKeyLink dimension="Worker" foreignKeyColumn="author" /><ForeignKeyLink dimension="Created" foreignKeyColumn="created" /><ForeignKeyLink dimension="Start" foreignKeyColumn="started" /><ForeignKeyLink dimension="Clients" foreignKeyColumn="cf_11100_id" /></DimensionLinks></MeasureGroup></MeasureGroups></Cube>To test this schema install Tomcat and get your external Mondrian server running as described in the documentation, then use Excel to do your JIRA OLAP.
The demo projects referenced in this blog have other templates defined, namely Contracts and Products. Feel free to extend the projects to your needs, you can create very complex JIRA reports using the technics described above.
There is a DEMO Mondrian server that you can connect to test JIRA OLAP in live:
|
Endpoint |
|
|
Username |
xmla |
|
Password |
xmlaxmla |